谷歌搜索引擎优化SEO创建并提交robots.txt文件
日期:2025年7月5日谷歌搜索引擎优化 (SEO)创建并提交 robots.txt 文件,您可以使用 robots.txt 文件控制抓取工具可以访问您网站上的哪些文件。robots.txt 文件应位于网站的根目录下。因此,对于网站 www.exam谷歌搜索引擎怎么优化

谷歌搜索引擎优化 (SEO)创建并提交 robots.txt 文件,您可以使用 robots.txt 文件控制抓取工具可以访问您网站上的哪些文件。robots.txt 文件应位于网站的根目录下。因此,对于网站 www.exam谷歌搜索引擎怎么优化
向搜索引擎要流量要订单!一个好网站不仅要满足用户需求还要符合SEO规则。
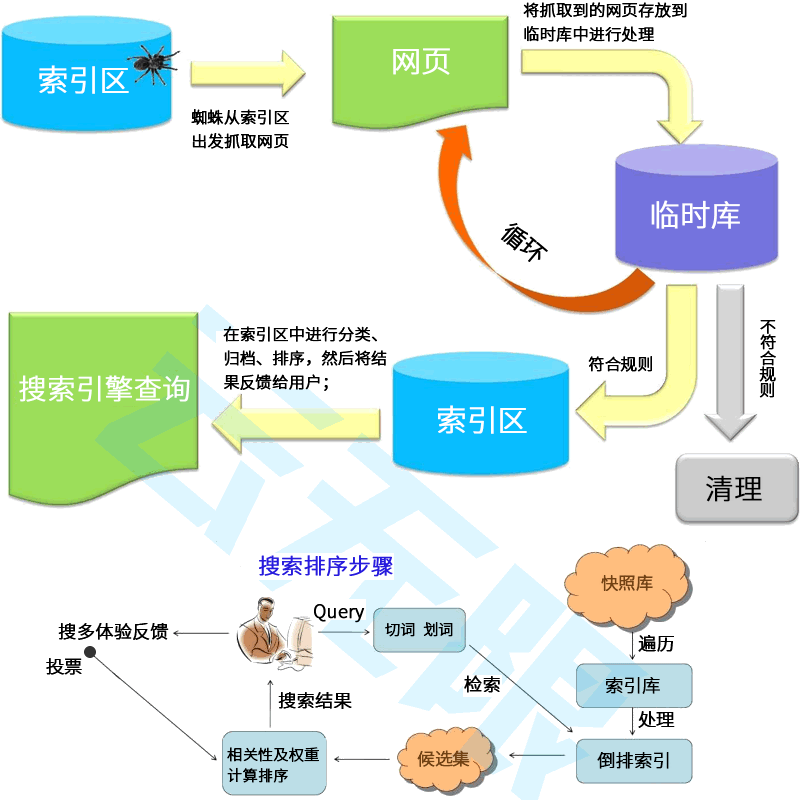
SEO的专业性远超你的想象!我们要做的是协助搜索引擎而不是欺骗它!它涉及到的不止是网站结构、内容质量、用户体验、外部链接这几个方面;还有算法的更替、蜘蛛的引导、快照的更新、参与排序的权重等。
一、让用户搜到你的网站是做SEO优化的目标,拥有精湛的SEO技术、丰富的经验技巧以及对SEO规则的深刻把握才有机会获得更多展现机会!
二、确保网站内容清晰、准确、易于理解,使用户能够轻松找到所需信息.使用简洁明了的标题和描述,帮助用户快速了解你的产品服务!
三、将企业的核心价值、差异化卖点、吸引眼球的宣传语等品牌词尽可能多的占位搜索前几页,增强用户印象,优化用户体验让访客信任你!
四、优化落地页引导用户咨询或预约留言,引用大型案例或权威报道彰显品牌实力,关注用户需求和反馈,不断优化产品服务让用户选择你!
让用户搜到你、信任你、选择你!
您可以使用 robots.txt 文件控制抓取工具可以访问您网站上的哪些文件。robots.txt 文件应位于网站的根目录下。因此,对于网站 www.example.com,robots.txt 文件的路径应为 www.example.com/robots.txt。robots.txt 是一种遵循漫游器排除标准的纯文本文件,由一条或多条规则组成。每条规则可禁止或允许特定抓取工具抓取相应网站的指定文件路径下的文件。除非您在 robots.txt 文件中另行指定,否则所有文件均隐式允许抓取。
下面是一个包含两条规则的简单 robots.txt 文件:
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml
以下是该 robots.txt 文件的含义:
1、名为 Googlebot 的用户代理不能抓取任何以 http://example.com/nogooglebot/ 开头的网址。
2、其他所有用户代理均可抓取整个网站。不指定这条规则也无妨,结果是一样的;默认行为是用户代理可以抓取整个网站。
3、该网站的站点地图文件路径为 http://www.example.com/sitemap.xml。
如需查看更多示例,请参阅语法部分。
要创建 robots.txt 文件并使其在一般情况下具备可访问性和实用性,需要完成 4 个步骤:
1、创建一个名为 robots.txt 的文件。
2、向 robots.txt 文件添加规则。
3、将 robots.txt 文件上传到您的网站。
4、测试 robots.txt 文件。
您几乎可以使用任意文本编辑器创建 robots.txt 文件。例如,Notepad、TextEdit、vi 和 emacs 可用来创建有效的 robots.txt 文件。请勿使用文字处理软件,因为此类软件通常会将文件保存为专有格式,且可能会向文件中添加非预期的字符(如弯引号),这样可能会给抓取工具带来问题。如果保存文件时出现相应系统提示,请务必使用 UTF-8 编码保存文件。
格式和位置规则:
● 文件必须命名为 robots.txt。
● 网站只能有 1 个 robots.txt 文件。
● robots.txt 文件必须位于其要应用到的网站主机的根目录下。例如,若要控制对 https://www.example.com/ 下所有网址的抓取,就必须将 robots.txt 文件放在 https://www.example.com/robots.txt 下,一定不能将其放在子目录中(例如 https://example.com/pages/robots.txt 下)。如果您不确定如何访问自己的网站根目录,或者需要相应权限才能访问,请与网站托管服务提供商联系。如果您无法访问网站根目录,请改用其他屏蔽方法(例如元标记)。
● robots.txt 文件可应用到子网域(例如 https://website.example.com/robots.txt)或非标准端口(例如 http://example.com:8181/robots.txt)。
● robots.txt 文件必须是采用 UTF-8 编码(包括 ASCII)的文本文件。Google 可能会忽略不属于 UTF-8 范围的字符,从而可能会导致 robots.txt 规则无效。
规则是关于抓取工具可以抓取网站哪些部分的说明。向 robots.txt 文件中添加规则时,请遵循以下准则:
● robots.txt 文件包含一个或多个组。
● 每个组由多条规则或指令(命令)组成,每条指令各占一行。每个组都以 User-agent 行开头,该行指定了组适用的目标。
● 每个组包含以下信息:
* 组的适用对象(用户代理)
* 代理可以访问的目录或文件。
* 代理无法访问的目录或文件。
● 抓取工具会按从上到下的顺序处理组。一个用户代理只能匹配 1 个规则集(即与相应用户代理匹配的比较早的最具体组)。
● 系统的默认假设是:用户代理可以抓取所有未被 disallow 规则屏蔽的网页或目录。
● 规则区分大小写。例如,disallow: /file.asp 适用于 https://www.example.com/file.asp,但不适用于 https://www.example.com/FILE.asp。
● # 字符表示注释的开始处。
Google 的抓取工具支持 robots.txt 文件中的以下指令:
● user-agent: [必需,每个组需含一个或多个 User-agent 条目] 该指令指定了规则适用的自动客户端(即搜索引擎抓取工具)的名称。这是每个规则组的首行内容。Google 用户代理列表中列出了 Google 用户代理名称。 使用星号 (*) 会匹配除各种 AdsBot 抓取工具之外的所有抓取工具,AdsBot 抓取工具必须明确指定。例如:
# Example 1: Block only Googlebot
User-agent: Googlebot
Disallow: /
# Example 2: Block Googlebot and Ad***ot
User-agent: Googlebot
User-agent: AdsBot-Google
Disallow: /
# Example 3: Block all but AdsBot crawlers
User-agent: *
Disallow: /
● disallow: [每条规则需含至少一个或多个 disallow 或 allow 条目] 您不希望用户代理抓取的目录或网页(相对于根网域而言)。如果规则引用了某个网页,则必须提供浏览器中显示的完整网页名称。它必须以 / 字符开头;如果它引用了某个目录,则必须以 / 标记结尾。
● allow: [每条规则需含至少一个或多个 disallow 或 allow 条目] 上文中提到的用户代理可以抓取的目录或网页(相对于根网域而言)。此指令用于替换 disallow 指令,从而允许抓取已禁止访问的目录中的子目录或网页。对于单个网页,请指定浏览器中显示的完整网页名称。对于目录,请用 / 标记结束规则。
● sitemap: [可选,每个文件可含零个或多个 sitemap 条目] 相应网站的站点地图的位置。站点地图网址必须是完全限定的网址;Google 不会假定存在或检查是否存在 http、https、www、非 www 网址变体。站点地图是一种用于指示 Google 应抓取哪些内容的理想方式,但并不用于指示 Google 可以抓取或不能抓取哪些内容。详细了解站点地图。 示例:
Sitemap: https://example.com/sitemap.xml
Sitemap: http://www.example.com/sitemap.xml
除 sitemap 之外的所有指令都支持使用通配符 * 表示路径前缀、后缀或整个字符串。
与这些指令均不匹配的行将被忽略。
如需有关每个指令的完整说明,请参阅 Google 对 robots.txt 规范的解释页面。
将 robots.txt 文件保存到计算机后,您便可以将其提供给搜索引擎抓取工具。没有一个统一工具可以帮助您完成这项工作,因为如何将 robots.txt 文件上传到网站取决于您的网站和服务器架构。请与您的托管公司联系,或在托管公司的文档中进行搜索;例如,搜索"上传文件 infomaniak"。
上传 robots.txt 文件后,请测试该文件是否可公开访问,以及 Google 能否解析该文件。
要测试新上传的 robots.txt 文件是否可公开访问,请在浏览器中打开无痕浏览窗口(或等效窗口),然后转到 robots.txt 文件的位置。例如:https://example.com/robots.txt。如果您看到 robots.txt 文件的内容,就可准备测试标记了。
Google 提供了两种测试 robots.txt 标记的方式:
1、Search Console 中的 robots.txt 测试工具。您只能针对您网站上可供访问的 robots.txt 文件使用此工具。
2、如果您是开发者,请了解并构建 Google 的开源 robots.txt 库,该库也用在 Google 搜索中。您可以使用此工具在计算机上本地测试 robots.txt 文件。
在您上传并测试 robots.txt 文件后,Google 的抓取工具会自动找到并开始使用您的 robots.txt 文件。您无需采取任何操作。如果您更新了 robots.txt 文件,并需要尽快刷新 Google 的缓存副本,请了解如何提交更新后的 robots.txt 文件。
下面是一些常见的实用 robots.txt 规则:
实用规则禁止抓取整个网站请注意,在某些情况下,Google 即使未抓取网站的网址,仍可能将其编入索引。TAG:谷歌搜索引擎怎么优化
如果你的网站无法从搜索引擎获取流量和订单!说明你从一开始就没有建立正确的SEO策略。

1、不限关键词数量,不限关键词指数,自由扩展.
2、更懂用户搜索习惯、更懂SEO规则、更懂运营.
3、专业团队实施,量化交付、效果持续有保障.

1、让网站结构、内部标签及HTML代码等更符合SEO规则.
2、客户指定关键词,不限关键词指数,不上首页不收费.
3、提升搜索蜘蛛抓取效率、收录效率、排名展现和有效访问.

1、竞争对手分析,了解同行营销策略以及行业趋势.
2、关键词保证到谷歌首页带来高价值流量及询盘.
3、涵盖Google、Bing、Yahoo等所有搜索引擎友好抓取.
世界上从不缺产品,缺的是把产品卖出去的方法!云优化是北京专业的SEO公司,专注百度、谷歌、搜狗、360等搜索引擎优化服务。我们更懂用户搜索习惯、更懂SEO规则、更懂网站运营和SEO排名技术。
同等成本,让您的关键词排名更靠前;同样市场,为您锁定目标客户快速吸引询盘
用SEO技术让客户搜到你!让你的品牌词、核心词和产品词尽可能多的占位搜索首页让客户信任你!改进用户体验直达落地页,引导用户咨询或预约留言,突出产品差异化卖点,用案例和权威报道增强品牌公信力让客户选择你!
SEO网站优化是一项持续且精细化的工作,而非一劳永逸。它要求优化师密切关注行业动态,深入分析数据,并根据这些洞察不断调整和优化策略。云优化坚信,在SEO的旅程中,耐心和毅力是不可或缺的驱动力。只有持之以恒地投入努力,不断优化网站,才能在激烈的网络环境中脱颖而出,取得更为优异的搜索引擎排名。

搜索引擎优化聚焦于站内优化、站外SEO及搜索体验。以客户为中心,追求转化价值最大化,遵循用户需求和搜索规则,是成功的关键。文章作为优化的一环,不仅要满足读者,还需符合搜索引擎抓取规则。被收录的文章才有机会参与排序。因此,明确主题、合理结构、段落清晰,并结合关键词与主题的SEO规则创作,是文章发布的必备要素。

搜索引擎优化(SEO)与竞价推广共同构成了搜索引擎营销(SEM),因其精准满足客户搜索需求,成为中小企业网站营销的优选。SEM利用搜索引擎这一流量枢纽,精准捕获目标客户,助力品牌建设。无论在国内市场,借助百度、搜狗、360,还是国际市场,利用谷歌、必应、雅虎,SEM都能成为您营销的强大助力。无论国内还是国际,SEM都是一项高效、精准的营销策略。

许多优化师对SEO效果持疑,但云优化认为,这更多与网站SEO策略相关。关键词排名虽受多因素影响,但正确思维和规范操作是关键。在网站上线前,深入分析并调整SEO,确保站内优化到位。平衡用户需求和搜索引擎规则,可提升网站转化率。因此,科学的SEO策略将助力网站取得更好效果。
